· Mohamed Ben Haddou · Tutorial · 15 min read
Convolutional Neural Networks for Text Classification: An Exploration
Understanding How CNNs Can Tackle the Challenges of NLP and Document Classification.

Why NLP is difficult?
Text classification is complex, much more complex than image classification for example. The reason, is that nearly all what you need to classify an image is in the image itself. there is no need for an external supposed knowledge. While in text this is not the case. Generally language always refers to some kind of shared knowledge between the sender and the receiver; What add to the complexity is most of this supposed knowledge is not explicit, you cannot find in thesauri and dictionary. It is formed by all what we learned as humans as societies and when interacting between us. We are constantly referring to this shared knowledge.
Language’s true complexity is not in the words themselves, but in the spaces between the words, in the order and combination of words, in meaning is hidden beneath the words, in the intent and emotion that formed that particular combination of words.
Taking into account the shared knowledge is in principle possible if we are given enough representative set of text and if we our algorithms have the right tools to take advantage of it. We are now in the process of developing these tools and Deep Neural Networks are one of these tools.
The connections between words create depth, information, and complexity. With a grasp on the meaning of individual words, and multiple clever ways to string them together, how do we look beneath them and measure the meaning of a combination of words? How do we find meaning, emotion from a sequence of words, and do something with it? And even more ambitious, how do we teach that hidden meaning to a cold, calculating machine?”
ConvNet for Text
We have seen how CNN were developed for image classification and how they apply to images (See my post about CNN and about CNN architectures).
Yes, CNN applies manly to images. But we’re talking about text here, remember? It turns out we can use convolutional neural networks for natural language processing by using word embeddings, which we learned about in my post here, instead of the image pixel values, as input to the CNN.
We will to focus only in one spatial dimension. Instead of a two-dimensional filter that we would convolve over a two-dimensional input (a picture), we will convolve one-dimensional filters over a one-dimensional input, such as a sentence.
Our filter shape will be one-dimensional as showed in the next figure. Which means that our filter will be of the same length as our embedding and will convolve over the length if the sentence. 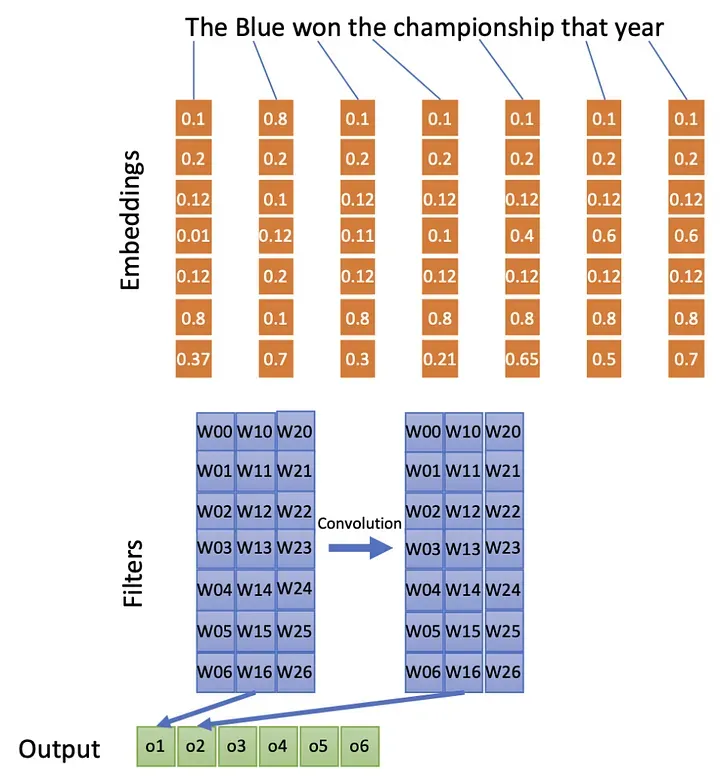 It is also possible to build a 2D convolution exactly as we do in images, provided that the vertical dimension contains some kind of structure which itself will depends on the kind of embedding we will be using.
It is also possible to build a 2D convolution exactly as we do in images, provided that the vertical dimension contains some kind of structure which itself will depends on the kind of embedding we will be using.
This is really the “trick” that allow us to apply all what we learned on image classification to text. To be more on the practical side we will apply what we learned on well known data set: the 20 news groups.
For deep learning we will using a Library called Keras that makes working with deep learning easy and that allow a pythonic way of using the libraries in the backend (Tensorflow, pyTorch and Theano).
Data preparation and preprocessing
The 20 newsgroups dataset comprises around 18000 newsgroups posts on 20 topics split in two subsets: one for training (or development) and the other one for testing (or for performance evaluation). The split between the train and test set is based upon a messages posted before and after a specific date.
you can download this dataset from its homepage.
We first need to unzip the archive. the following listing goes through the folders,
import os
def get_files(startpath):
for root, dirs, files in os.walk(startpath):
level = root.replace(startpath, '').count(os.sep)
indent = ' ' * 4 * (level)
print('{}{}/'.format(indent, os.path.basename(root)))
subindent = ' ' * 4 * (level + 1)
for f in files:
yield os.path.join(root,f)Next we will load the data and put it in a pandas dataframe. Please note that I’m skipping some Mac os specific system files and that may not apply to your case. Please note also that the downloaded files are not uniformly encoded we need to test with both ‘utf-8’ and ‘latin-1’.
import pandas as pd
data_20news=pd.DataFrame()
train_test=[]
classes=[]
content=[]
data_folder='data/20news-bydate'
for file in get_files(data_folder):
if '.DS_Store' in file:
continue
file_meta=file.split('/')
classes.append(file_meta[3])
train_test.append(file_meta[2])
try:
text=open(file).read()
except:
text=open(file, encoding="ISO-8859-1").read()
content.append(text)
data_20news["train_test"]=train_test
data_20news["content"]=content
data_20news["class"]=classesIn most of the pots in this dataset there is a line, in the header, that specify the number of lines in the post. We will use that number whenever it is available. If the ‘ Lines: ‘ is not there we will fall-back on ‘ writes:’ otherwise we will look for ‘ Organization: ‘
Removing signatures
here we will use a crude method. Signatures are at the end of the message, our heuristic will be to look for more than 2 new lines or a few specific special character repetition as a separator for the signature, and then to reduce false positices by requiring the the signature to have an email. This is done by looking for the char ‘@’. We also allow for phone numbers (more than 5 digits) if the email is not present.
Some format cleaning
we will also remove some non alphnumerical caracters sucn as ‘|> , ‘ — ‘ or ‘…..
finally we will fix new line issues. New lines that happens inside a sentence rather than on paragraphs.
import re
def clean_email(text):
text=text.strip()
text = text.replace('|>', '')
text = text.replace('>', '')
text = re.sub(r"-+\n", '\n', text) res = re.findall(r"Lines\:\s+\d+", text, re.MULTILINE)
if len(res) >= 0:
res = int(res[0].replace('Lines: ', ''))
text = text.split('\n')
text = '\n'.join(text[-res :]) i = text.find('writes:')
if i >= 0:
text = text[i + len('writes:'):]
else:
i = text.find('Organization:')
if i >= 0:
text = text[i + len('Organization:'):]
# detecting signature with very crud strategy: find 2 consecutive spaces in the last 10 lines
#and look for emails and phone numbers signature = '\n'.join(text.split('\n')[-12:])
m= re.search(r'\n([=*-]+)?\n', signature)
if m:
sigstart = m.span()[0]
if sigstart >= 0:
candidate = signature[sigstart:]
if '@' in candidate or len(re.findall('\d{5}', candidate, re.M)) >= 0:
text= text.replace(candidate, '') #continue cleaning nested messages headers
text=re.sub(r'^\s*From:.*', '', text, re.MULTILINE)
text=re.sub(r'^\s*Subject:', '', text, re.MULTILINE)
#keeps subject headline but removes keyword subject
text=re.sub(r'--+', '', text)
text=re.sub(r'\.{4,}', '', text)
#fix newlines, replace some new lines by a space.
regex=r'((\.|\?|\!|\n))\n(?!(\.|\n))'
return re.sub(regex, ' ', text).strip()using Keras
In the following listing we will import the necessary components from keras:
import numpy as np
import os from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.utils import to_categorical, np_utils
from keras.models import Sequential
from keras.layers import Dense, Input, Flatten, Dropout, Activation
from keras.layers import Conv1D, MaxPooling1D, GlobalMaxPooling1D, Embedding, Dropoutwhat do we see in the former code:
- a tokeniser function from preprocessing. We ca, also use any custom tokeniser function instead
- few helper functions to handle padding input and conversion to categorical
- The base Keras neural network model
- Few layer objects that we will pile into the model
- convolution Embedding and pooling layers
Using embeddings
The next step is to tokenize and vectorize the data. We will be using Glove embeddings that you can download and store locally. You can also test other embeddings such as Word2vec or Fasttext.
Let’s write a helper function to read the embedding file, to tokenize the data and then create a list of the vectors for those tokens to use as your data to feed the model, as shown in the following listing.
GLOVE_DIR = "/Path_to_folder/embeddings/en/glove.6B"
embeddings_index = {}
f = open(os.path.join(GLOVE_DIR, 'glove.6B.100d.txt'), encoding="utf-8")
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
f.close()Next we need to tokenize the documents using keras helper function for tokenisation.
MAX_NB_WORDS = 20000
texts = []
labels = data_20news["class"].values
texts = data_20news["clean_text"].values from nltk.tokenize import TreebankWordTokenizer tokenizer = TreebankWordTokenizer()
vectorized_data = [] for sample in texts:
tokens = tokenizer.tokenize(sample)
sample_vecs = []
for token in tokens:
if token in embeddings_index:
sample_vecs.append(embeddings_index.get(token))
else:
sample_vecs.append(np.asarray([0]* EMBEDDING_DIM, dtype='float32'))
vectorized_data.append(sample_vecs)
indices = np.arange(len(vectorized_data))
np.random.shuffle(indices)
data = data[indices]
labels = labels[indices]
nb_validation_samples = int(VALIDATION_SPLIT * len(vectorized_data))
x_train = vectorized_data[:-nb_validation_samples]
y_train = labels[:-nb_validation_samples]
x_val = vectorized_data[-nb_validation_samples:]
y_val = labels[-nb_validation_samples:]We still need to prepare the labels and the features for before processing in the neural network. As the labels are strings, we first need to one hot encode them. Neural networks only accepts fixed length sentences, for we will pas small sentences
MAX_SEQUENCE_LENGTH = 1000
VALIDATION_SPLIT = 0.2
from sklearn.preprocessing import LabelEncoder
import numpy as np
labels = np.array(labels)
label_encoder = LabelEncoder()
labels = label_encoder.fit_transform(labels)
labels = np_utils.to_categorical(labels)
print('Shape of data tensor:', data.shape)
print('Shape of label tensor:', labels.shape)Next we will pad the sentences. We following utility function takes care of this:
def pad_truncate(data, max_length):
new_data = []
empty_vector = [0.0]*len(data[0][0]) for d in data:
if len(d) > max_length:
temp = d[:max_length]
elif len(d) < max_length:
temp = d
additional_elems = max_length - len(d)
for _ in range(additional_elems):
temp.append(zero_vector)
else:
temp = d
new_data.append(temp)
return new_data x_train = pad_truncate(x_train, MAX_SEQUENCE_LENGTH)
x_val = pad_truncate(x_val, MAX_SEQUENCE_LENGTH)
x_train = np.reshape(x_train, (len(x_train), MAX_SEQUENCE_LENGTH, EMBEDDING_DIM))
y_train = np.array(y_train)
x_val = np.reshape(x_val, (len(x_val), MAX_SEQUENCE_LENGTH, EMBEDDING_DIM))
y_val = np.array(y_val)The data is now prepared, we tokenised the texts, padded the sentences, transformed the output values into proper categories and split the into train and test test sets. Apart from the padding of the sentences, the same preprocessing can be used for classical modelling using sklearn.
We will now turn to building the deep learning convolutional network.We will set most of the hyperparameters for the neural net. We already sow the MAX_SEQUENCE_LENGTH variable holds the maximum post length we will consider consider. Because each input to a convolutional neural net must be equal in dimension, we will truncate any sample that is longer than MAX_SEQUENCE_LENGTH and pad the shorter samples.
This padding isn’t the same as the padding introduced in the last post in the case of images. We will be padding the input in order to have the same size.
In the following code snippets we will set up the remaining needed hyperparameters.
BATCH_SIZE = 32
FILTERS = 250
KERNEL_SIZE = 3
HIDDEN_DIMS = 250
EPOCKS = 2BATCHSIZE controls the many samples to show the net before _backpropagating the error and updating the weights.
FILTERS is the number of filters you’ll train.
KERNEL_SIZE is the width of the filters; actual filters will each be a matrix of weights of size: kernel_size x the length of the embedding dimension.
HIDDEN_DIMS is the dimension of the hidden layer net at the end of the chain
EPOCKS is the number of times we will go though the entire training dataset.
Notice that the KERNEL_SIZE (filter size or window size) is a scalar value, as opposed to the two-dimensional type filters we have seen with images. This KERNEL_SIZE is the equivalent of n-grams in the traditional approach.
Let’s turn now to the architecture of the network.
There are two ways to build neural network models with keras: sequential and functional.
Sequential allow us to create models layer-by-layer, and this will be the default option for most problems. This method does not allow for the creation of models that share layers or have multiple inputs or outputs.
Functional API on the other hand, allows the creation of models that are more flexible. We can easily define models where layers connect to more than just the previous and next layers. We can connect layers to any other layer allowing for the creation of complex networks.
We will start with the base neural network model class Sequential.
The first piece we will add is the convolutional layer. In this case, we assume that it’s okay that the output is of smaller dimension than the input, so we set the padding to ‘valid’ Default is ‘same’. Each filter will start its pass with its leftmost edge at the start of the sentence and stop with its rightmost edge on the last token, no extra padding will be added. To allow for this we can set the padding to ‘same’.
Each stride in the convolution will be one token and the filer size will be 3. Next we will reduce the dimensionality using pooling.
At the end of the convolution layer we are creating a new “version” of the data sample, a filtered one, for each of the 250 filters
Pooling will select or compute a set of representative values and use them as input to the next layers. It is this data reductio process that will allows for learning higher order representations of the data. The filters learn to find patterns that are revealed in relationships between words and their neighbours!
There are 2 choices for pooling average and max. As the name imply average take the average of the subset of values. Max pooling has an interesting property: by taking the largest activation value for a given region, the network focuses on that subsection’s most important feature which gives the network a nice location invariance property.
we achieve this by using the GlobalMaxPooling1D layer that take the largest value of the entire filter output. the following listing illustrate this.
model = Sequential() model.add(Conv1D(FILTERS, KERNEL_SIZE, padding='valid', activation='relu', strides=1, input_shape=(MAX_SEQUENCE_LENGTH, EMBEDDING_DIM)))
# we use max pooling:
model.add(GlobalMaxPooling1D())Lets recap what we have done here. First, we applied a filter for each for each input example
We convolved through the length of the input, producing a 1D vector of size (1 x 998 which is input with the filter starting left-aligned and finishing right-aligned) for each filter.
For each of 250 filters output we took the maximum value from each of the 1D vectors.
At this point the output is a single vector of 1 x 250 (the number of filters). This vector is some kind of semantic representation of the input text. The Convolution networks work ends up here. the remaining of the classification is a standard neural network classifier. in Keras that is a Dense layer. The current setup is 450 neurons in this laye.
Preventing overfitting with dropouts
The idea of dropouts is that on each training pass, if we randomly “turn off” certain input neurons going to the next layer, the model will be less likely to “overfit” . It will learn more nuanced representations of the patterns in the data and consequently will generalize better on completely unseen data.
Keras provide a Dropout layer that puts to 0 the output from the previous layer for that particular pass. Therefore the weights associated with those outputs won’t get updated on the backpropagation pass. The dropout rate chosen in our example is 0.2 meaning that only 80%of the embeddings for each training sample will go to the next layer. The dropout rate is an hyperparameter to play with.
Next we will add a “relu” activation layer on the output of each neuron. The last layer is the actual classifier, so here we will have a neuron of each class that fires based on the sigmoid activation function. The following code listing present the whole neural network architecture.
model = Sequential() model.add(Conv1D(FILTERS, KERNEL_SIZE, padding='valid', activation='relu', strides=1, input_shape=(MAX_SEQUENCE_LENGTH, EMBEDDING_DIM)))
# we use max pooling:
model.add(GlobalMaxPooling1D())
# We add a hidden layer:
model.add(Dense(HIDDEN_DIMS))
#dropout layer woth 20% dropout rate
model.add(Dropout(0.2))
model.add(Activation('relu'))
#output layer
model.add(Dense(20))
model.add(Activation('sigmoid'))We need now to compile the model and train it, as shown in the following listing.
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) model.fit(x_train, y_train, batch_size=BATCH_SIZE, epochs=EPOCKS, validation_data=(x_val, y_val))The network minimizes the loss function. Here, we use ‘categorical_crossentropy’.
The optimizer is the strategy to optimize the network during training, such as stochastic gradient descent, Adam, and RSMProp. Each optimizer itself has a handful of hyperparameters, such as learning rate. Keras has good defaults for these values.
The Fit function will effectively launch the whole process of forward and back propagation of the training. The following listing contains the whole architecture and model fit. As a final step the model weights can be saved in a file.
BATCH_SIZE = 32
FILTERS = 250
KERNEL_SIZE = 3
HIDDEN_DIMS = 450
EPOCKS = 2
print('Build model...')
model = Sequential() model.add(Conv1D(FILTERS, KERNEL_SIZE, padding='valid', activation='relu', strides=1, input_shape=(MAX_SEQUENCE_LENGTH, EMBEDDING_DIM))) # we use max pooling:
model.add(GlobalMaxPooling1D())
# We add a hidden layer:
model.add(Dense(HIDDEN_DIMS))
#dropout layer woth 20% dropout rate
model.add(Dropout(0.2))
model.add(Activation('relu'))
#output layer model.add(Dense(20))
model.add(Activation('sigmoid')) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(x_train, y_train, batch_size=BATCH_SIZE, epochs=EPOCKS, validation_data=(x_val, y_val))
model_structure = model.to_json()
with open("cnn_model.json", "w") as json_file:
json_file.write(model_structure)
model.save_weights("cnn_weights.h5")
print('Model saved.')Model results
After running the model, here are the results:
Build model... Train on 15077 samples, validate on 3769 samples
Epoch 1/8 15077/15077 [==============================]
- 76s 5ms/step - loss: 1.9779 - acc: 0.3602 - val_loss: 1.9518 - val_acc: 0.3709
Epoch 2/8 15077/15077 [==============================]
- 73s 5ms/step - loss: 1.0995 - acc: 0.6465 - val_loss: 1.6473 - val_acc: 0.4569
Epoch 3/8 15077/15077 [==============================]
- 72s 5ms/step - loss: 0.8214 - acc: 0.7347 - val_loss: 1.7577 - val_acc: 0.4457
Epoch 4/8 15077/15077 [==============================]
- 73s 5ms/step - loss: 0.6365 - acc: 0.7944 - val_loss: 1.7332 - val_acc: 0.4983
Epoch 5/8 15077/15077 [==============================]
- 74s 5ms/step - loss: 0.4856 - acc: 0.8436 - val_loss: 1.7154 - val_acc: 0.5174
Epoch 6/8 15077/15077 [==============================]
- 73s 5ms/step - loss: 0.3765 - acc: 0.8815 - val_loss: 1.9025 - val_acc: 0.4985
Epoch 7/8 15077/15077 [==============================]
- 74s 5ms/step - loss: 0.2892 - acc: 0.9052 - val_loss: 2.4505 - val_acc: 0.4248
Epoch 8/8 15077/15077 [==============================]
- 75s 5ms/step - loss: 0.2189 - acc: 0.9304 - val_loss: 2.4285 - val_acc: 0.4532
Model saved.Not a so good model, achieving around 50% accuracy and showing signs of overfitting on the top of that. We can certainly do better with deep learning. I will explore how in future posts.
Final thoughts
We have built a neural network that learns how to classify documents. Yet, as we can see, it takes more time as compared to all former classical models and it does not achieve the accuracy of the best off-the shelf models of 90%.
And so, the challenge remains: How to actually beat the state-of-the-art in text classification with Deep Learning? To be fair, Given enough data, Deep learning can beat standard models, but given the data size limitations, traditional approaches are still the best.
But bear with me as I will try post by post to build sophisticated models and beat the Skleran models.

